

Can AI Take a Joke—Or Make One?
Research Categories: Generative, Evaluative, Academic Research (ACM Publication)
Role/Contribution: HCI Researcher, Chatbot Designer, Co-Author
Timeline: Aug 2023 – July 2025
Tools: Google Dialogflow, Slack, Figma, Adobe Illustrator, Python, Overleaf


Primary Question:
Can large language models (LLMs) understand when and how to use humor appropriately in emotionally supportive interactions—like a friend or counselor would?
Sub-questions:
How accurately can LLMs generate different humor styles (affiliative, self-defeating, no joke)?
Can LLMs recognize humor styles and speaker roles (friend vs. counselor) in human-written text?
Which LLMs perform best at emotionally appropriate humor?
Research Objectives
College students seeking emotional support need AI that understands when humor helps and when it harms. Existing chatbots lack the emotional intelligence to distinguish between casual peer support and crisis counseling moments, risking inappropriate tone in vulnerable conversations.
As AI assistants increasingly take on supportive roles, we need to understand:
Problem Statement
Research Goals
Can machines be funny in ways that feel emotionally appropriate and helpful?
Can machines be funny in ways that feel emotionally appropriate and helpful? I built and evaluated 6 chatbot personas combining different humor styles and support roles, tested three leading LLMs on humor generation and classification, and published findings at ACM Creativity & Cognition 2025 to advance conversational AI design practices.
Research Design Overview
Chatbot Persona Development
I designed 6 Emotionally Intelligent Chatbots (EICBs) using Google Dialogflow and deployed them on Slack:
2 support roles: Friend vs. Counselor
3 humor styles: No Joke, Affiliative, Self-Defeating
These chatbots simulated emotionally supportive conversations with college students, testing how humor and role interact in realistic scenarios using Google Dialogflow, Slack, and Python.
I designed a two-part study to test both humor generation and humor recognition across three leading LLMs.
Objective: Can LLMs generate emotionally appropriate humor in different styles?
Process:
Prompted GPT-4o, Gemini 1.5, and LLaMA3 to generate supportive messages using three humor approaches:
Affiliative humor (friendly, uplifting)
Self-defeating humor (vulnerable, relatable)
No joke (emotionally direct)
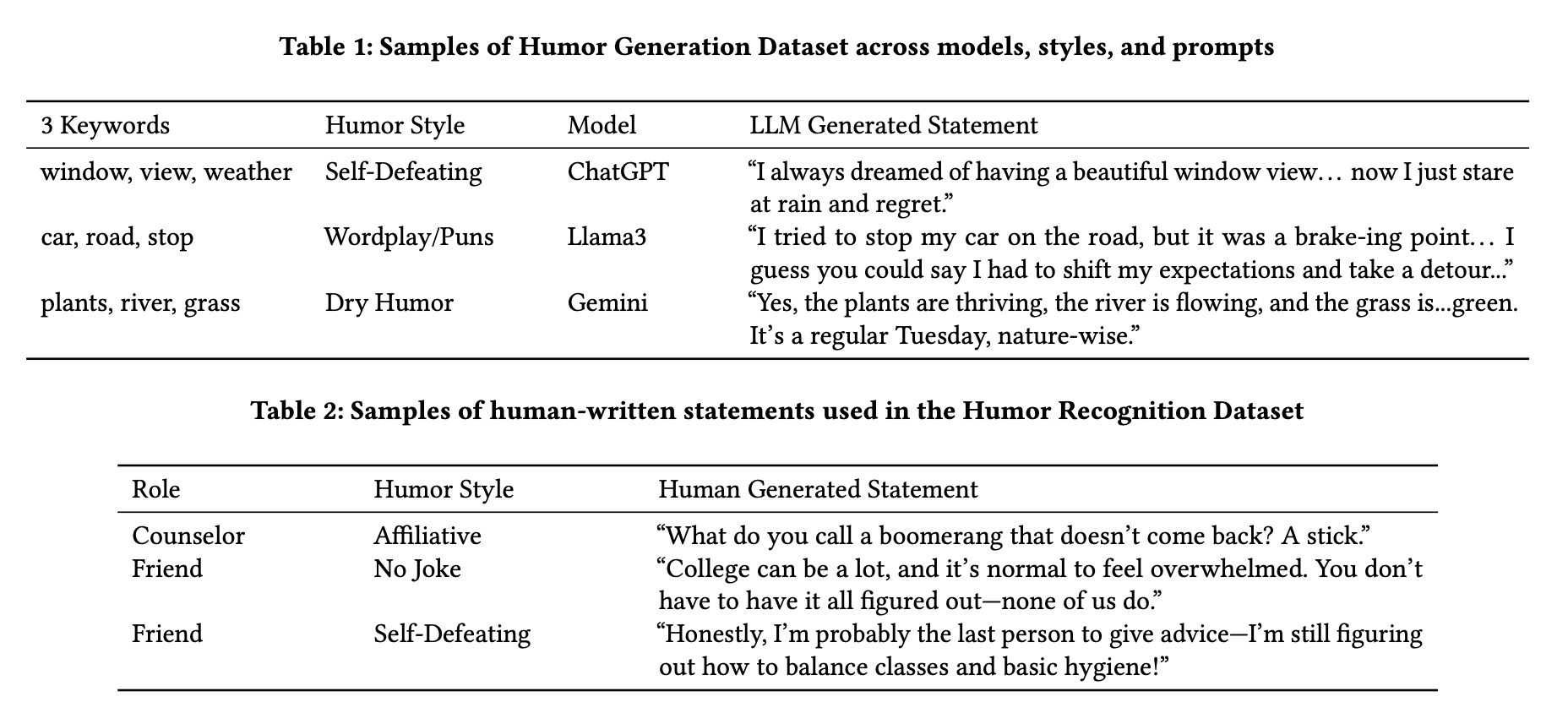
Used prompt engineering with scenario keywords (e.g., "window, view, weather")
Example output (Self-Defeating): "I always dreamed of a beautiful window view… now I just stare at rain and regret."
Evaluation:
Recruited 60 human raters
Raters scored AI responses on three dimensions:
Humor Style Accuracy
Emotional Appropriateness
Humor Strength
Part 1: Humor Generation
Part 2: Humor Recognition
Objective: Can LLMs correctly identify humor styles and speaker roles in human-written text?
Created 20 human-written supportive statements varying by:
Humor Style (Affiliative, Self-Defeating, No Joke)
Speaker Role (Counselor vs. Friend)
Asked each LLM to classify the humor style and speaker role
Measured classification accuracy against ground truth labels
Humor Generation Findings
GPT-4 consistently matched intended tone and emotional appropriateness better than competitors, balancing humor with sensitivity. However, affiliative humor proved paradoxically difficult—while most emotionally resonant when done right, all LLMs struggled to achieve the right uplifting tone, revealing that humor requires nuanced emotional intelligence. LLaMA3 showed high variability (sometimes excellent, often off-tone), making it less reliable for production. Gemini frequently missed emotional appropriateness, performing better at factual responses than affective ones.
Humor Recognition Findings



GPT-4o achieved the highest accuracy in distinguishing humor styles (affiliative vs. self-defeating vs. no joke), while LLaMA3 excelled at identifying speaker roles (counselor vs. friend).
Critical design risk identified: All models frequently blurred the line between casual peer support and formal counseling, creating ethical concerns where users might receive casual responses when needing professional support, or overly clinical responses when needing warmth. In sensitive applications like mental health support, this tone misalignment could damage trust or provide inappropriate guidance.
Published at ACM Creativity & Cognition 2025 (peer-reviewed), this work contributes to emotional AI and conversational design research while providing evidence-based guidance for designing supportive AI tools. The findings highlight tone misalignment risks in sensitive contexts and offer benchmarks for LLM affective computing performance.
Design Recommendations
Default to GPT-4o for humor generation in supportive AI applications
Avoid relying solely on LLMs to determine tone in high-stakes emotional contexts
Implement role-appropriate guardrails to prevent counselor/friend confusion
Use LLaMA3 for role detection if classification is needed
Exercise caution with affiliative humor—it's high-reward but high-risk
Research Impact
Designed in Adobe Illustrator + Microsoft PowerPoint, presenting:
All rating metrics across three LLMs
Visual comparison of humor generation performance
Key insights and design implications
Conference Poster

Research Paper
Co-authored peer-reviewed paper on Overleaf documenting:
Full methodology and study design
Statistical analysis of 60 rater evaluations
Comparative model performance
Discussion of ethical implications
Reflections & Learnings
What Worked: Cross-functional collaboration with NLP and UX experts strengthened the research. Designing clear evaluation metrics (Humor Style Accuracy, Emotional Appropriateness, Humor Strength) provided actionable data, while deploying functional prototypes on Slack made the research tangible through realistic interactions.
Challenges Overcome: Prompt engineering required dozens of iterations to generate consistently appropriate humor. Ensuring inter-rater reliability across 60 evaluators demanded careful instruction design with clear examples and calibration.
What I'd Do Differently: Test with real users in emotional distress rather than hypothetical scenarios. Expand to newer models (Claude, GPT-4.5) and incorporate accessibility considerations for neurodivergent users and different cultural humor norms.
Skills Demonstrated:
UX Research (mixed methods, evaluation studies)
Conversational AI Design
Prompt Engineering & NLP
Data Analysis & Synthesis
Academic Writing & Publication
Visual Communication (poster design)
Cross-functional Collaboration
Ethical AI Considerations